Introduction
COROUTINE is a C++ library for coroutine sequencing, which Keld Helsgaun published in May 1999.
Coroutine primitives & state
The facilities of the library are based on the coroutine primitives provided by the programming language SIMULA.
-
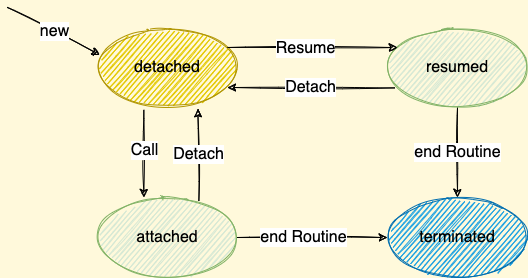
Resume(Coroutine *Next): resume the execution of a coroutine -
Call(Coroutine *Next): start the execution of a coroutineThe execution procedure of
ResumeandCallare the same: 1. suspending the current thread, 2. executing(start/resume) the target thread. The only difference between them is that the Call will Establish a relationship between caller and callee, whereas the Resume doesn’t. -
Detach(): suspending/terminating the current coroutine and resume the caller of current coroutine
State transitions of a coroutine:
Implementation
Two different implementations of the library are provided. The first implementation is based on the copying of stacks in and out of C++’s runtime stack. In the second implementation, all stacks of coroutines reside in the runtime stack (i.e., no stacks are copied).
All the following sections are based on the assumptions of the stack growing downwards.
Copy-Stack
TLDR
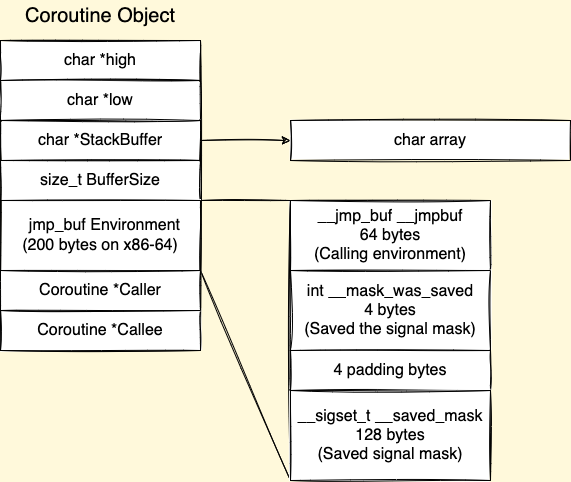
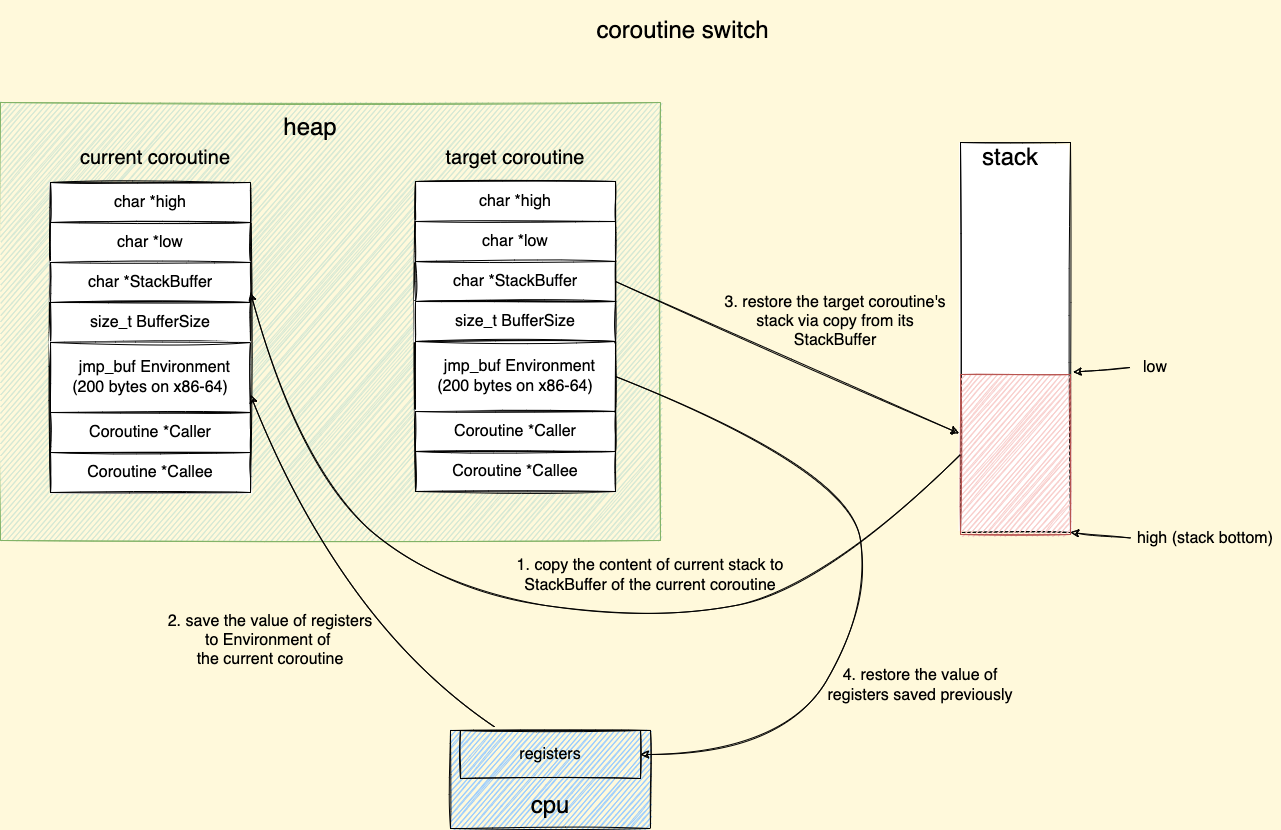
Use a StackBuffer on the heap to store/resume stack content and registers of a coroutine so that a coroutine could be suspended/continued by memcpy straightforward.
Explain in Detail (Assuming stack grows down)
The struct of a coroutine struct (assuming stack grows down):
Procedure of coroutine switch (step 1,2 is suspending current coroutine, step 3,4 is resuming target coroutine):
Pondering
-
What would happen if size of
StackBufferof the target coroutine is large than stack current used?An undefined behavior would occur if the
memcpywere carried out without checking the size of stack current used. The program may jump to another statement far away; it may also crash with a segmentation fault; anything could happen.To avoid it, we allocating memory on stack continually until the stack is large enough to hold
StackBufferof the target coroutine. -
Does
BufferSizealways equals toHigh - Lowfor a coroutine?No,
BufferSize >= High - Low.BufferSizeis the length ofStackBuffer, sinceStackBuffernever shrink, theBufferSizestands for the maximum size of stack content the buffer ever hold. This is also the reason of usingHigh - Lowinstead ofBufferSizewhen the stack restore was carrying out. -
Why
StackBuffernever shrink?In order to reduce the frequency of memory allocation & free.
Share-Stack
TLDR
Let all coroutine stacks share C++’s runtime stack, and jump between to achieve context switch.
Explain in Detail
Data structures (assuming stack grows down):
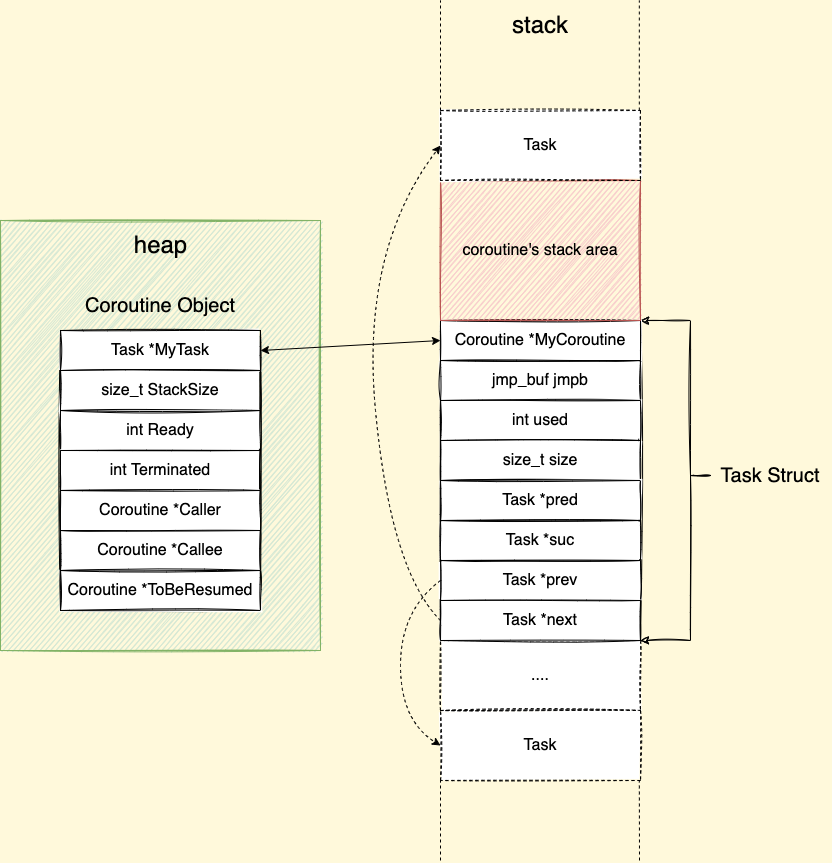
Annotation:
pred, suc : predecessor and successor in a doubly linked list of unused tasks
prev, next: pointers to the two adjacent tasks
StackSize: size of available stack memory, pre-allocated
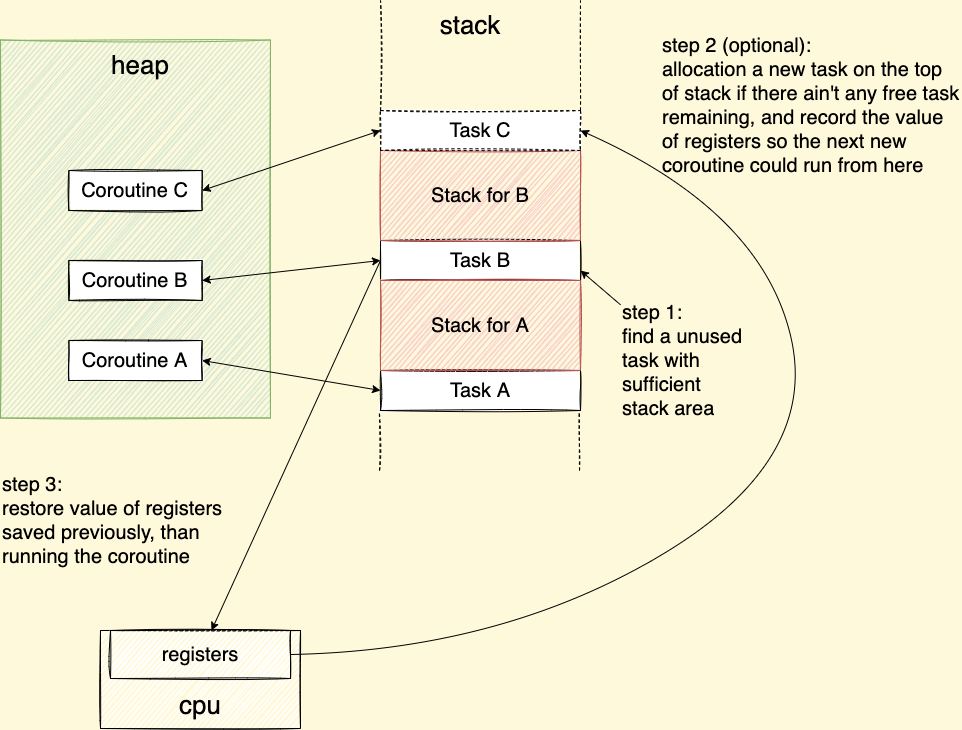
Procedure of coroutine switch:
Pondering
-
What if the stack requested at the coroutine initialization was insufficient?
Stack of the program will be disrupted, anything horrible could happen.
-
Can we prevent the coroutine from stack overflow?
As far as I know, we can’t.
-
How does we put the struct
taskto the start of the corresponding coroutine’s stack?We doesn’t put the
taskstruct to the start of a coroutine’s stack. All we do it make sure there are at least 1 unclaimedtaskstruct on the stack all the time. When a new coroutine was called, thetaskwould assigned to it and the coroutine would running on the stack space just behind it. -
Why
pred/sucandprev/nextpointers are provided at the same time, whether one of the two groups could be removed?The
prev/nextpointers are necessary which maintain the memory layout of our program, including:- allocation new task
- merge free memory blocks on the stack
- split memory block on necessary.
Where as
pred/sucpointers are optional, they just speed up the procedure in searching for unused task. -
What’s the usage of
Coroutine *ToBeResumed?*ToBeResumedintends to indicate a coroutine calling a specific coroutine on ending instead of returning directly, but not used for the library currently. -
Why the state of coroutine (value of registers, stored in
jmp_buf) not recovered to initial state when a coroutine terminated?There is no need to recover
jmp_bufafter the coroutine is terminated since theTaskwould be marked as free. When the next new coroutine is fitted in this freeTask, the new state will be stored tojmp_buf, execution of the program would not bother with the obsoleted state.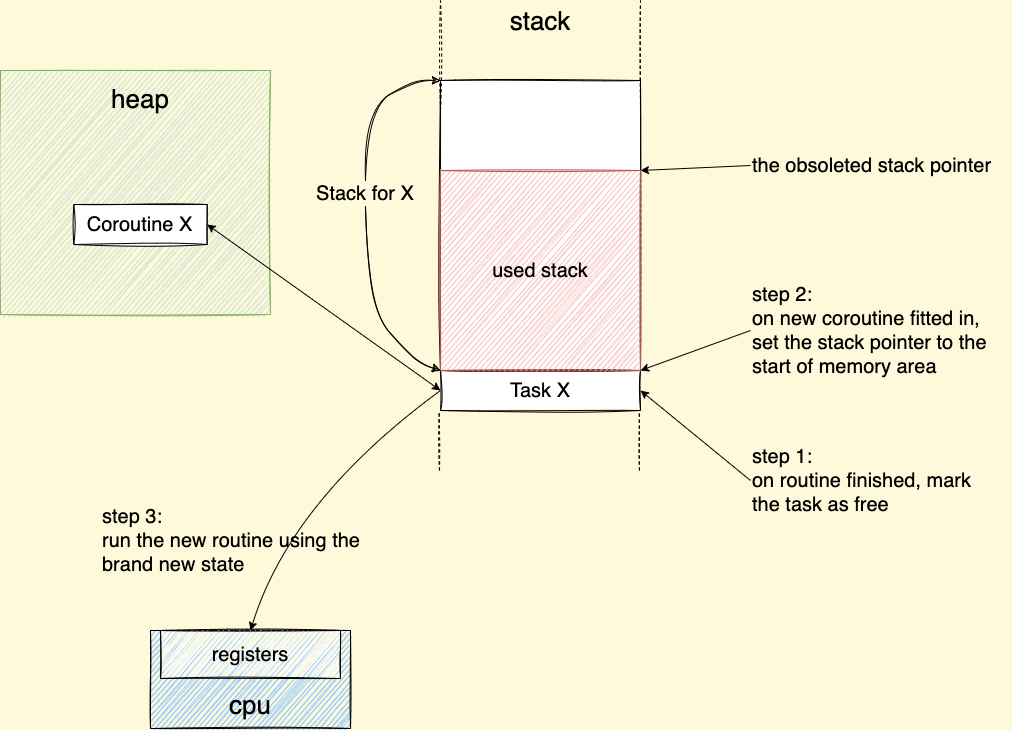
Comparison of the two implementations
(Arranged from the original report)
| copy-stack implementation | share-stack implementation | |
|---|---|---|
| memory overhead on AMD64 (per coroutine) | 256 bytes (size of Coroutine) + the largest size of stack the coroutine stored ever | 256 bytes (size of Task) + 48 bytes (size of Coroutine) + stack memory allocated but not used |
| context switch overhead | memory copying for the stack content + registers storing + registers restoring | registers storing + registers restoring |
| ease of use | user does not need to bother about stack sizes for coroutines | requires the maximum stack size of each coroutine to be specified |
| restrictions in use | - | - |
| robustness | ok | on stack overflow, the program will crush or produce meaningless results without any notification |
| memory use | each suspended coroutine must keep a copy of its stack content on the heap | if maximum stack size specified is way too large, a lot of unnecessary memory is wasted |
| maintenance | simple | way too complex (a bunch of setjmp and longjmp ) |
| portability | ok | ok |
Reference
- COROUTINE (Keld Helsgaun)
- setjmp.h source code [glibc/setjmp/setjmp.h] - Woboq Code Browser
- setjmp.h source code [glibc/sysdeps/x86/bits/setjmp.h] - Woboq Code Browser
- setjmp.S source code [glibc/sysdeps/x86_64/setjmp.S] - Woboq Code Browser
- longjmp.c source code [glibc/setjmp/longjmp.c] - Woboq Code Browser
- __longjmp.S source code [glibc/sysdeps/x86_64/__longjmp.S] - Woboq Code Browser